Free Cloud Interview Guide to crush your next interview. Plus, real-world answers for cloud interviews, and system design from a top AWS Solutions Architect.
MLOPS - What and Why ⚙
|
Hello Reader, MLOps is gaining quite the buzz these days, given the rise of Gen AI. In today's newsletter, let's find out what MLOps is and why it is becoming so popular. This edition of the newsletter is written by Vijay Kodam, Principal Engineer at Nokia, and AWS Community Builder. MLOps is set of practices that streamline and automate machine learning workflows. It integrates DevOps practices into machine learning workflows to streamline machine learning operations. Why do we need MLOps?Most of the time, as part of the machine learning workflow, they go through EDA, data prep, model training, tuning, then model deployment and monitoring just to find out that it is not ready for production. You have to repeat the process all over again and retrain the model. Since the machine learning workflows were manual and several teams were involved in this process at different stages, it took lot of time and effort to maintain it. Streamlining and automating such manual process speeds up time to product and decreases manual errors and risks. This leads to scalability of managing and monitoring thousands of machine learning models. This allows the data scientists and engineers to focus on model development and innovation.
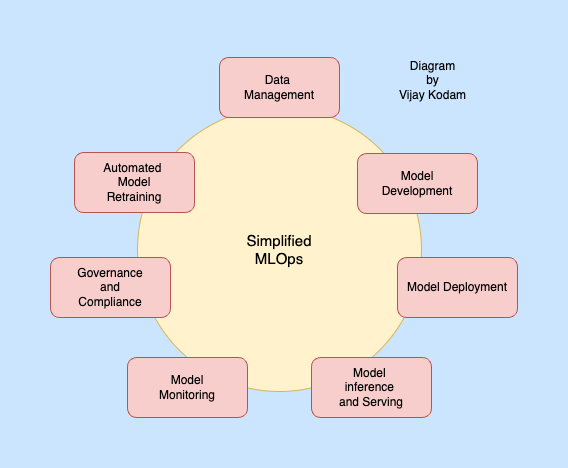
Key components of MLOpsMachine learning lifecycle has several interconnected stages and all of these key components together make up MLOps. I have been going through various MLOps guides from AWS, Google, IBM and Databricks and realized all of them mostly follow the same key components. Data ManagementData is the new oil. For ML data makes or breaks a model. It is the backbone of any machine learning model. Fetching right data, storage, preprocessing the data for model development and versioning are very important. Primarily this stage consists of Exploratory Data Analysis (EDA) which includes exploring and understanding data. Data preparation and feature engineering are also part of this step, which includes collecting data, processing data. Feature engineering preprocesses raw data into a machine-readable format. It optimizes ML model performance by transforming and selecting relevant features. Some MLOps implementations separate EDA and Data preparation into two stages. Here are some of the tools used for data management:
Model DevelopmentThis stage involves the design, training, tuning, and evaluation of machine learning models. Here are some of the tools and services used as part of model development:
Model deploymentFocuses on packaging models, shipping them and deploying them to production environments. This step ensures the model is accessible via an API, microservice or application. Here are the tools and services used for model inferencing, serving and model deployment:
Model inference and servingModel inference and serving involves making it available for use by applications and end users. It focuses on querying the deployed model to generate predictions. Services like Amazon SageMaker Endpoints, Google Vertex AI Endpoints, Azure Machine Learning Endpoints, TensorFlow Serving, KServe and MLflow Models are used. Model MonitoringAfter deployment, continuous monitoring is essential to ensure that models perform as expected and maintain their accuracy over time. Prometheus + Grafana is the opensource stack for monitoring. Good to get started. Model monitoring services: AWS SageMaker Model Monitor, Evidently. There are also custom monitoring solutions like Kubeflow pipelines. Governance and ComplianceThis key component ensures ML models are developed and deployed responsibly and ethically. Model explainability can be done using Local Interpretable Model-agnostic Explanations (LIME) and SHAP (SHapley Additive exPlanations). MLflow supports Audit and compliance. Amazon Macie handles security. Data and Model Lineage can be done using MLflow, Amazon SageMaker Model Registry and Google Cloud Vertex AI Model Registry. Automated model retrainingAutomated model retraining involves retraining the ML model when its performance degrades or when new data becomes available. In this stage model retraining is triggered when specific conditions are met, then retrain the model using latest data and then evaluate the retrained model. ConclusionAs the adoption of machine learning is skyrocketing, the importance of MLOps is now higher than ever. MLOps helps automate and streamline machine learning operations. I have tried listing some of the tools used in MLOps is every key component/stage of machine learning workflow. Which tools or services you choose for MLOps depends on whether you are running on AWS, Google, Azure, Databricks, baremetal or opensource. Vijay regularly posts about AWS, AI/ML, EKS, Kubernetes, and Cloud computing-related topics. Visit https://vijay.eu/posts/ for all his articles, and follow him on LinkedIn. If you have found this newsletter helpful, and want to support me 🙏: Checkout my bestselling courses on AWS, System Design, Kubernetes, DevOps, and more: Max discounted links AWS SA Bootcamp with Live Classes, Mock Interviews, Hands-On, Resume Improvement and more: https://www.sabootcamp.com/
Keep learning and keep rocking 🚀, Raj |
Fast Track To Cloud
Free Cloud Interview Guide to crush your next interview. Plus, real-world answers for cloud interviews, and system design from a top AWS Solutions Architect.
Hello Reader, On March 31, 2026, one Anthropic engineer forgot to add a single line to a config file. That omission shipped a 59.8MB debug file alongside the Claude Code npm package, exposing 512,000 lines of TypeScript code across 1,900 files to the entire internet. Within hours, it was mirrored on GitHub and dissected by thousands of developers. Most coverage got lost in the drama of it. The real story is what the code reveals about how AI agent tools actually work, and where they are...
Hello Reader, Almost every cloud and Gen AI interview right now includes this question. And almost every candidate gets it wrong. Not because they don't know Gen AI. But because they know too many terms and connect none of them. Let's fix that today. Question: What is an AI Agent? Common but average answer - "An agent can perform complex tasks without a prompt." Why is this average? It doesn't explain the superpower of an AI agent. It doesn't show how agents are different from a simple...
Hello Reader, Everyone's building AI agents. If you've been following our newsletters, on MCP, on agent memory, on getting hired, you know that agents are the next evolution. They connect to your tools, they take actions on your behalf, and they're moving from demos into production faster than most organizations are ready for. But the question almost nobody is asking: who is securing the AI itself and how? To answer that, we welcome Adam Bluhm, Principal AI Architect @HiddenLayer (Ex-AWS)....